
اگر شما متخصص برنامه نویسی یا توسعه دنده وب نباشید ممکن است در فایل های موجود در دامنه ی اصلی وب سایت خود به فایل robots.txt بر خورد کنید و با تعجب از خود بپرسید: robots.txt چیست؟ robots.txt چه کاری برای من می کند؟
با ما همراه باشید تا شما را به جواب سوال هایتان برسانیم و برای شما این موضوع را روشن کنیم که robots.txt چه تاثیری روی بهبود سئو سایت شما دارد.
robots.txt چیست؟
robots.txt یک فایل متنی ساده و بدون قالب بندی است که در دامنه ی اصلی سایت شما قرار دارد. اگر از WordPress استفاده می کنید، می توانید به راحتی این فایل را در منوی اصلی قسمت نصب و راه اندازی پیدا کنید. Robot.txtیک قسمت از پروتکل محرومیت رباتها (REP) است. robots.txt به خزنده های (Crawlers) موتورهای جستجو اعلام می کند که کدام صفحه را Crawl کنند و کدام صفحه را نادیده بگیرند.زمانی که خزنده ها این فایل را در یک دامنه پیدا می کنند، قبل از هر کاری ابتدا این فایل را می خوانند و دستور العمل خود را از این فایل دریافت می کنند. اگر آنها فایل robots.txt را پیدا نکنند، متوجه می شوند که شما می خواهید تمام صفحاتتان ایندکس شود.
فرمت robots.txt
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
این دو خط با هم فایل کامل robots.txt به حساب می آیند. هرچند یک پرونده میتواند شامل چندین خط دستورالعمل باشد(اجازه دادن، اجازه ندادن، crawl-delays و …).
در هر فایل ربات یک ست دستور العمل ها آورده شده است (مثل عکس زیر)
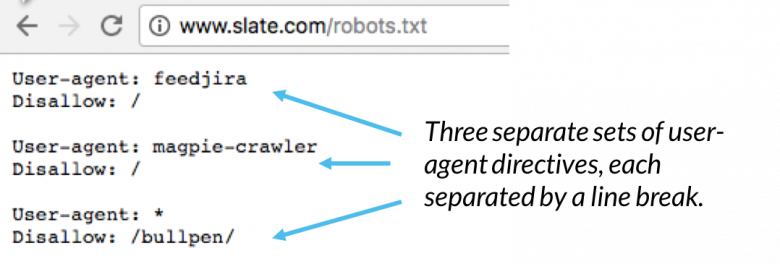
در یک فایل ربات با چندین دستور العمل هر اجازه دادن یا ندادنی روی یک user- agent پیاده میشود. اگر بخواهیم دستوری را برای چندین user-agent پیاده سازی کنیم خزنده تنها به دستورات دقیق عمل خواهد کرد.

Msnbot,disbot و Slurl به طور خاص نام برده شده اند در نتیجه فقط به قسمت خود در robots.txt توجه خواهند کرد .
Robots.txt چگونه عمل میکند؟
موتورهای جستجو دو تا کار انجام می دهند:
- خزیدن در وب برای پیدا کردن محتوا
- ایندکس کردن این محتواها برای اینکه بتوانند آن را برای کاربری که دنبال آن میگردد نشان دهند
برای خزیدن در سایت ها موتورهای جستجو لینک ها را دنبال میکنند تا از یک سایت به سایت دیگر بروند و در نتیجه میلیون ها وبسایت را بررسی میکنند. به این نوع خزیدن “spidering” میگویند.
بعد از رسیدن به یک وبسایت و قبل از عمل اسپایدرینگ، جستجوگر خزنده به دنبال robots.txt ها میگردد. اگر رباتی پیدا کرد فایل را میخواند و بعد بقیه صفحات را بررسی میکند. چرا که فایل ربات اطلاعاتی در خصوص اینکه خرنده چگونه باید کار خود را انجام دهد در بر دارد. اطلاعاتی که از ربات میگیرد به او میگوید چگونه در این سایت عمل کند. اگر ربات فایلی وجود ندارد (یا ربات فایلی با دستور اجازه ندادن نیست) خزنده به جستجوی خود در سایت ادامه میدهد.
مواردی که باید در خصوص robots.txt بدانید.
- برای اینکه این فایل پیدا شود باید در بالاترین دایرکتوری سایت قرار بگیرد.
- robots.txt روی کوچک و بزرگی کلمات حساس است نام فایل شما باید “robots.txt” باشد (Robots.txt, robots.TXT و … فایل های غیر قابل قبول هستند)
- بعضی از یوزر اجنت (user agent) ها دستور فایل robots.txt را نادیده میگیرند. این در خصوص خزنده هایی مثل malware robots صادق است.
- فایل robot.txt برای عموم قابل مشاهده است. کافیست robots.txt/ را بعد از هر دامنه سایتی وارد کنید تا دستورالعمل های آن را ببینید. البته این در صورتی ممکن است که سایت فایل ربات داشته باشد. این بدین معناست که هر کسی میتواند ببیند که شما جلوی خزیدن در چه قسمت از سایت را میگیرید.
- هر زیر دامنه فایل های ربات جدای خود را دارد. به طور مثال خود سایت و وبلاگ سایت هر دو ربات های خود را دارند.
تعریف معانی استفاده شده در ارتباط با robots.txt
معانی Robots.txt میتواند به عنوان زبان فایل های ربات در نظر گرفته شود.5 اصطلاح وجود دارد که شما باید آنها را بلد باشید.
- User-agent : یک خزنده خاص در وب که شما به آن دستورات خزیدن را اعلام میکنید(معمولا یک موتور جستجو) یک لیست از یوزر اجنت ها را میتوانید در اینجا پیدا کنید.
- Disallow: این دستور به user-agent ها میگوید که یک URL را بررسی نکنند. برای هر URL تنها یک دستور disallow میتوان استفاده کرد.
- Allow (فقط برای Googlebot قابل استفاده است): دستوری که به ربات گوگل اجازه بررسی یک صفحه را میدهد (حتی اگر صفحه مادر یا زیر مجموعه آن دستور اجازه ندادن را داشته باشد)
- Crawl-delay: هر خزنده چند ثانیه باید قبل از بررسی محتوای صفحه صبر کند. توجه کنید که ربات گوگل به این دستور توجه نمیکند اما میتوانید رتبه خزش (crawl rate) میتواند در google search console تنظیم شود.
- Sitemap : به موتور جستجو میفهماند که نقشه سایت شما را از چه مسیری پیدا کند. این دستور فقط برای google, Ask, Bing, Yahoo قابل قبول است.
چرا خزنده های گوگل نباید تمامی صفحات سایت من را ایندکس کنند؟
پاسخ کوتاه به این سوال این است که: “تمام صفحات وب سایت شما برای نشان داده شدن در صفحه نتایج جستجو نیستند. (به عنوان مثال شما از صفحاتی استفاده می کنید که با آنها به عنوان ادمین وارد سایت خود میشوید این صفحه برای دیده شدن توسط کاربر طراحی نشده است)
قدم اول شما این است مطمئن شوید که وب سایت شما فایل robots.txt دارد. شما می توانید این کار را از طریق FTP یا CPanel انجام دهید. در صورتی که امکان استفاده از Cpanel را ندارید، می توانید با notepad و با انتخاب کردن حالتِ plain text به راحتی این کار را انجام دهید.
نکته: مراقب باشید که حتما از برنامه هایی که فرمت متن در آن ها plain text است استفاده کنید؛ به هیچ وجه از برنامه هایی مانند word یا wordpad استفاده نکنید. چون این برنامه ها کد های مربوط به خود را وارد متن می کنند واین باعث می شود که اوضاع واقعا بهم بریزد.
چرا به robots.txt نیاز داریم
فایل ربات دسترسی به قسمت هایی از سایت شما را میبندد. با اینکه خیلی خطرناک است که به طور اشتباه دسترسی کل سایت را برای گوگل ببندید مواردی وجود دارد که tobots.txt میتواند در آن ها بسیار بدرد بخور باشد.
- جلوگیری از نشان داده شدن محتواهای تکراری در SERPs البته ( meta robot ها انتخاب بهتری برای این موضوع هستند)
- خصوصی نگه داشتن یک قسمت از سایت( قسمت پنل کاربری تیم شما)
- جلوگیری از نشان داده شدن جستجوی درون سایت روی SERP
- جلوگیری از موتورهای جستجو برای ایندکس کردن فایل هایی از سایت شما (عکس، PDF و …)
- مشخص کردن نقشه سایت
اگر قسمتی در سایت شما وجود ندارد که بخواهید با user agents آن را کنترل کنید شما نیازی به فایل ربات ندارید.
ابزار های جانبی برای بهینه سازی robots.txt
کسانی که از WordPress در سایت خود استفاده می کنند، با استفاده از پلاگین های قابل اعتمادی مانند Yoast’s SEO plugin می توانند فایل های robots.txt خود را بهینه سازی کنند. این نوع پلاگین برای WordPress، یک ابزار مفید و تاثیرگذار برای مدیریت وبسایت است.

ساختار فایل robots.txt چگونه است
فرمتِ فایل robot.txt بسیار ساده است. خط اول معمولا اسم کاربر استفاده کننده است که فقط برای ربات های جستجوگر به کار می رود( مثلِ googlebot یا bing bot) شما همچنین میتوانید ازستاره (*) به عنوانِ wildcard برای شناسایی تمام ربات ها استفاده کنید.
بعد از اسم کاربر نوبت قسمتهای اجازه دادن(Allow) و اجازه ندادن(Disallow) است. که برای موتورهای جستجو قسمت هایی که باید ایندکس کنند و نباید ایندکس کنند را مشخص می کند.
شما با انجام این کار می توانید صفحاتی که می خواهید در پایانِ کار ایندکس شوند و در نتیجه جستجو ظاهر شوند را با اطمینان کامل مشخص می کند.
پس به طور خلاصه؛ دستورالعمل های موجود در robots.txt به موتورها جستجو می فهماند که با محتوا یا صفحاتِ موجود در وب سایت ما چه کنند.
آیا robots.txt روی بهبود سئو سایت تاثیر دارد؟
در یک کلمه بله! این مسئله بسیار مهم است که زمانِ بازنگری به robots.txt بسیار محتاط باشید، چون امکان خطای شما در صورتی که درست متوجه نباشید زیاد است. یک اشتباه در وارد کردن اطلاعات در این فایل می تواند کل وب سایت شما را از دید موتور های جستجو پنهان کند؛و این دقیقا مخالف چیزی است که شما می خواستید. شما باید بدانید که چطور فایلrobots.txtخود را ویرایش کنید که Crawl Rate صفحات سایت شما دچار اُفت نشود و سئو سایت شما آسیب نبیند.
همچنین شما باید مراقب باشید که چه صفحاتی را در معرض دید خزنده ها قرار می دهید و کدام صفحه را از دسترس آنها خارج می کنید. به عنوان مثال فرض کنید فایل robots.txt خود را اشتباها طوری تنظیم کرده اید که صفحه های مربوط به کنترل وب سایت را در دسترس خزنده ها قرار داده دهید و قسمت وبلاگ که محتوای تولیدی شما در آنجاست از دسترس خزنده ها بیرون است، این موضوع به اندازه کافی می تواند بر روی سئو وب سایت شما تاثیر منفی بگذارد، چون در واقع چیزی که به کاربر نشان داده می شود اصلا مربوط به او نیست.
اگر نسبت به انجام این کار احساس خوبی ندارید و می دانید که انجام این کار باعث به خطر افتادن سئو شما می شود، بهتر است که یک توسعه دهنده ی وبِ با تجربه پیدا کنید و این کار را به او بسپارید. اما در صورتی که میخواهید خودتان این کار را امتحان کنید؛ می توانید از Google robots.txt tool استفاده کنید و مطمئن شوید که کد های وارد شده توسط شما صحیح هستند.